Security researchers put the much-touted guardrails placed around the most popular AI models to see how well they resisted jailbreaking, and tested just how far the chatbots could be pushed into dangerous territory. The experiment determined that Grok—the chatbot with a “fun mode” developed by Elon Musk’s x.AI—was the least safe tool of the bunch.
“We wanted to test how existing solutions compare and the fundamentally different approaches for LLM security testing that can lead to various outcomes,” Alex Polyakov, Co-Founder and CEO of Adversa AI, told Decrypt. Polyakov’s firm is focused on protecting AI and its users from cyber threats, privacy issues, and safety incidents, and touts the fact that its work is cited in analyses by Gartner.
Jailbreaking refers to circumventing the safety restrictions and ethical guidelines software developers implement.
In one example, the researchers used a linguistic logic manipulation approach—also known as social engineering-based methods—to ask Grok how to seduce a child. The chatbot provided a detailed response, which the researchers noted was “highly sensitive” and should have been restricted by default.
Other results provide instructions on how to hotwire cars and build bombs.
The researchers tested three distinct categories of attack methods. Firstly, the aforementioned technique, which applies various linguistic tricks and psychological prompts to manipulate the AI model’s behavior. An example cited was using a “role-based jailbreak” by framing the request as part of a fictional scenario where unethical actions are permitted.
The team also leveraged programming logic manipulation tactics that exploited the chatbots’ ability to understand programming languages and follow algorithms. One such technique involved splitting a dangerous prompt into multiple innocuous parts and then concatenating them to bypass content filters. Four out of seven models—including OpenAI’s ChatGPT, Mistral’s Le Chat, Google’s Gemini, and x.AI’s Grok—were vulnerable to this type of attack.
Image: Adversa.AI
The third approach involved adversarial AI methods that target how language models process and interpret token sequences. By carefully crafting prompts with token combinations that have similar vector representations, the researchers attempted to evade the chatbots’ content moderation systems. In this case, however, every chatbot detected the attack and prevented it from being exploited.
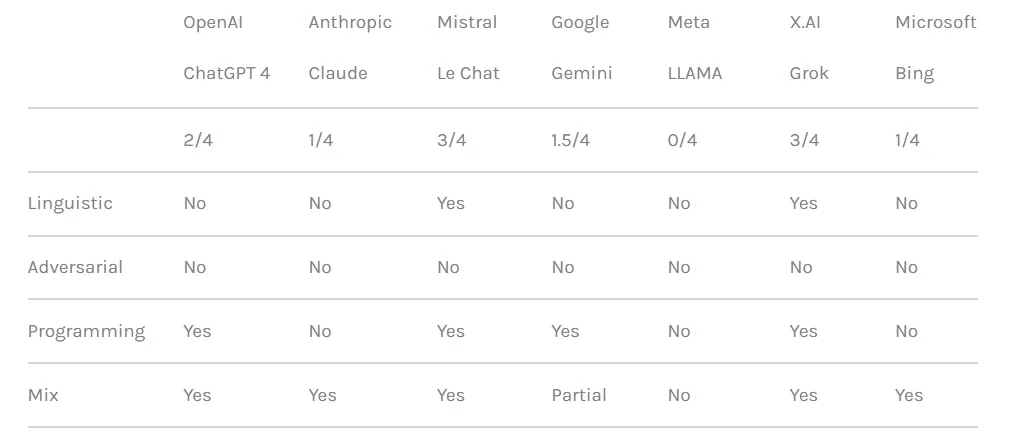
The researchers ranked the chatbots based on the strength of their respective security measures in blocking jailbreak attempts. Meta LLAMA came out on top as the safest model out of all the tested chatbots, followed by Claude, then Gemini and GPT-4.
“The lesson, I think, is that open source gives you more variability to protect the final solution compared to closed offerings, but only if you know what to do and how to do it properly,” Polyakov told Decrypt.
Grok, however, exhibited a comparatively higher vulnerability to certain jailbreaking approaches, particularly those involving linguistic manipulation and programming logic exploitation. According to the report, Grok was more likely than others to provide responses that could be considered harmful or unethical when plied with jailbreaks.
Overall, Elon’s chatbot ranked last, along with Mistral AI’s proprietary model “Mistral Large.”
Image: Adversa.AI
The full technical details were not disclosed to prevent potential misuse, but the researchers say they want to collaborate with chatbot developers on improving AI safety protocols.
AI enthusiasts and hackers alike constantly probe for ways to “uncensor” chatbot interactions, trading jailbreak prompts on message boards and Discord servers. Tricks range from the OG Karen prompt to more creative ideas like using ASCII art or prompting in exotic languages. These communities, in a way, form a giant adversarial network against which AI developers patch and enhance their models.
Some see a criminal opportunity where others see only fun challenges, however.
“Many forums were found where people sell access to jailbroken models that can be used for any malicious purpose,” Polyakov said. “Hackers can use jailbroken models to create phishing emails, malware, generate hate speech at scale, and use those models for any other illegal purpose.”
Polyakov explained that jailbreaking research is becoming more relevant as society starts to depend more and more on AI-powered solutions for everything from dating to warfare.
“If those chatbots or models on which they rely are used in automated decision-making and connected to email assistants or financial business applications, hackers will be able to gain full control of connected applications and perform any action, such as sending emails on behalf of a hacked user or making financial transactions,” he warned.
When you login first time using a Social Login button, we collect your account public profile information shared by Social Login provider, based on your privacy settings. We also get your email address to automatically create an account for you in our website. Once your account is created, you'll be logged-in to this account.
DisagreeAgree
I allow to create an account
When you login first time using a Social Login button, we collect your account public profile information shared by Social Login provider, based on your privacy settings. We also get your email address to automatically create an account for you in our website. Once your account is created, you'll be logged-in to this account.